สวัสดีครับในวันนี้ผมจะมาแนะนำ การทำนายสิ่งต่าง ๆ โดยใช้ Python ซึ่งเราจะใช้ Library หลายตัว ได้แก่ pandas สำหรับสร้าง สิ่งที่เรียกว่า "DataFrame" ซึ่งจะทำให้เราทำงานกับข้อมูลได้ง่ายขึ้น numpy ใช้สร้าง Numpy Array ที่ง่ายต่อการคำนวณณ และ sklearn ซึ่งเราจะใช้ทำ Feature Selection หรือการเลือก Attributes ที่เหมาะสมที่สุด (มี Correlation กับคำตอบที่เราต้องการทำนายที่สุด) โดยที่ sklearn จะมี Functions ต่าง ๆ ให้เราเลือกใช้ เช่น chi2 (Chi-squared) และ mutual_info_classif ในการช่วยให้เราสามารถคำนวณได้ง่ายขึ้น
Data Understanding
ในบทความนี้ผมจะใช้ข้อมูลจาก Dataset ที่ชื่อ "Heart Disease Prediction Dataset" จาก www.kaggle.com/datasets/krishujeniya/heart-diseae เพื่อมาทำนายแนวโน้มที่จะเป็นโรคหัวใจ
ในไฟล์จะมี Attributes 14 ตัว ได้แก่
age: อายุของคนไข้ (หน่วยเป็นปี)
sex: เพศของคนไข้ (1 = ชาย, 0 = หญิง)
cp: ชนิดของการเจ็บหน้าอก (1-4)
trestbps: ความดันโลหิตขณะพัก (หน่วยเป็น มม.ปรอท)
chol: Serum cholesterol หน่วย mg/dl
fbs: น้ำตาลในเลือดขณะอดอาหาร > 120 mg/dl (1 = จริง; 0 = เท็จ)
restecg: ผลการตรวจคลื่นไฟฟ้าหัวใจขณะพัก (0-2)
thalach: อัตราการเต้นของหัวใจสูงสุด
exang: หลอดเลือดหัวใจตีบที่เกิดจากการออกกำลังกาย (1 = จริง; 0 = เท็จ)
oldpeak: ST depression จากการออกกำลังกายหรือนอนพัก
และ Attribute ที่เป็น หัวใจหลักเลยก็คือ target คือ บอกผลการสำรวจว่าคนไข้คนดังกล่าวเป็นโรคหัวใจหรือไม่ (1 = เป็น 0 = ไม่เป็น)
Data Cleaning
โดยปกติแล้วจะมีการทำ Data Cleaning ก่อนเพื่อให้ข้อมูลง่ายต่อการคำนวณ ซึ่งจะมี methods (functions) หลายตัวใน Pandas ที่เราสามารถใช้ทำ Data Cleaning ได้ เช่น การเติมค่าว่างด้วยค่าเฉลี่ย หรือด้วยค่า 0 การลบ columns หรือ แถวที่ซ้ำ หรือที่ข้อมูลขาดหายเยอะ เป็นต้น แต่ในบทความนี้ข้อมูลที่เรามี ค่อนข้างที่จะดี มีการทำ Data Cleaning และ Transformation มาแล้วอย่างดี คือ มีการกำหนดประเภท ชาย = 1 หญิง = 0 มีการกำหนดระดับข้อมูลที่สามารถจัดเรียงได้ เช่น low, medium, high ให้เป็นตัวเลข 1,2,3,4 เป็นต้น
เริ่มลงมือทำ
เรามาเริ่มทำกันเลยดีกว่า! ก่อนแรกผมจะสร้าง DataFrame ขึ้นมาเก็บไว้ใน ตัวแปรที่ชื่อ df ซึ่งเราจะอ่านค่าจากในไฟล์ .csv ที่เราดาวน์โหลดมา โดยใช้ method ที่ชื่อ read_csv ของ pandas เราจะได้ DataFrame ที่พร้อมใช้งาน
import pandas as pd
import numpy as np
df = pd.read_csv("./heart-disease.csv")
df #แสดง Dataframe
จากนั้นเราจะแยก ส่วนที่เป็น เฉลย ซึ่งก็คือ column สุดท้ายที่ชื่อ "target" มาไว้ในตัวแปรที่ชื่อ Y ส่วน columns ที่เหลือเราจะเก็บไว้ใน X เราจะเรียกวิธีนี้ว่า การ "Split XY" เพื่อที่เราจะนำ XY ไป Train และ ทดสอบโดยการนำ Y ออก และใช้ข้อมูลจากใน X มาทำนายหา Y
df_arr = df.values
X = df_arr[:,0:len(df_arr[1])-2] #นำเอา Columns ทั้งหมด ยกเว้น columns สุดท้ายที่เป็นเฉลย
Y = df_arr[:,len(df_arr[1])-1] #Column ที่เก็บข้อมูลเฉลยว่า เป็นหรือไม่เป็น)
Feature Selection
แต่โดยปกติ columns หลาย ๆ อัน ที่เก็บข้อมูลมา อาจจะไม่มีความเกี่ยวข้องอะไรเลยในการทำนาย เราจึงต้องมีการทำสิ่งที่เรียกว่า "Feature Selection" คือการเลือกเอาแค่ columns ที่มีความสัมพันธ์กับผลลัพธ์เท่านั้น เช่น ค่าในบาง columns เมื่อมีมาก ความเป็นไปได้ที่ผลลัพธ์จะออกเป็น 1 นั้นมีมากขั้น เราจะเรียกว่า ความสัมพันธ์แบบ แปรผันตรง (Direct Variation) ในทางตรงกันข้าม อาจมีบาง columns ที่ยิ่งค่ามาก ก็ลดความเป็นไปได้ที่ผลลัพธ์จะออกเป็น 1 ลง เราจะเรียกว่าความสัมพันธ์แบบ แปรผกผัน (Inverse Variation)
ทั้งแบบ Direct Variation และ Inverse Variation เป็นสิ่งที่เราต้องการนำมาใช้ Train Model ของเรา ซึ่งผมจะใช้ chi2 (Chi-squared) ในการทดสอบหา columns ที่มีความสัมพันธ์ทั้งสองแบบ มา 10 columns โดยใช้ฟังก์ชั่น SelectKBest โดยกำหนด score_func เป็น chi2 และกำหนดจำนวน columns ที่ต้องการ เป็น k=10 ดังนี้
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#เลือก columns ที่ดีที่สุดมา 10 กลุ่ม
feature_selection = SelectKBest(score_func=chi2, k=10)
fit = feature_selection.fit(X, Y)
X_selection = fit.transform(X) #Columns ใน X ทั้งหมดที่ผ่านการคัดเลือก
หากเราต้องการดูว่า columns ไหนได้รับการเลือกบ้าง เราจะเขียนดังนี้
feature_names = fit.get_feature_names_out()
feature_names
จะได้ว่า columns ที่ถูกเลือกก็คือ 'x2', 'x4', 'x7', 'x8', 'x9' และ 'x11' ซึ่งก็คือ cp, chol, thalach, exang, oldpeak และ ca
การ Train Model แบบ Linear
โดยปกติแล้วในการ Train Model อะไรสักอย่าง เราจะแบ่งข้อมูลจำนวน 80% เป็นข้อมูลที่ใช้สำหรับการ Train ส่วนอีก 20% เป็นข้อมูลที่ใช้สำหรับการ Test ซึ่งจะเป็นข้อมูลส่วนที่ Model ไม่เคยเห็นมาก่อน
เราจะเห็นได้ว่าข้อมูล 20% ที่ใช้ในการ Test จะไม่ไปอยู่ใน 80% แน่นอน ดังนั้น Model ที่ Fit ควรจะสามารถทำนาย 20% หลังซึ่งเป็นข้อมูลที่ Model ไม่เคยเห็นมาก่อนได้ เราจึงจะสามารถเห็นได้ว่า Model ที่เราได้มานั้น Underfit หรือ Overfit หรือเปล่า ด้วยการทดสอบดังกล่าว
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
#แยก Train Set กับ Test Set ออกจาก X และ Y โดยกำหนด test_size=0.2 หมายถึง จำนวน Test Set = 20%
#random_state=42 คือการเลือกการสุ่ม Test, Train Set ให้มีค่า 42 หมายถึงจะสุ่มชุดเดิม ๆ ในการรัน ทุกครั้ง ค่า 42 สามารถเปลี่ยนเป็นอะไรก็ได้
X_train, X_test, Y_train, Y_test = train_test_split(X_selection, Y, test_size=0.2, random_state=42)
print("X train size: "+str(len(X_train)))
print("X test size: "+str(len(X_test)))
print("Y train size: "+str(len(Y_train)))
print("Y test size: "+str(len(Y_test)))
lr = LinearRegression()
lr.fit(X_train, Y_train)
Y_linear_train_prediction = lr.predict(X_train)
Y_linear_test_prediction = lr.predict(X_test)
จากนั้นเราจะนำข้อมูลการทำนาย Y จากการ Train มา หา mean_squared_error และ r2_score กับข้อมูล Y ที่เราใช้ในการ Train ก่อนหน้า
ค่า mean_squared_error จะบอกได้ว่า การทำนายจาก regression line มีความคลาดเคลื่อนไปจากข้อมูลจริง (data points) มากเท่าใด ยิ่งค่ามีมาก แสดงว่า ค่าที่ทำนายห่างจากความเป็นจริงมาก
ค่า r2 scores (Coefficient of determination) อธิบายง่าย ๆ คือ ค่านี้บอกเราได้ว่า การทำนายจาก attributes หรือ columns ที่เราเลือก ซึ่งเราคัดมาแล้วว่าพวกนี้เป็น ตัวแปรที่ขึ้นต่อกัน (dependent variable) กับผลลัพธ์ หรือ Y ที่สุด สามารถทำนายได้ดีมากเท่าใด ค่า 1 คือ Model สามารถทำนายความสัมพันธ์ของตัวแปรต่าง ๆ ที่เราเลือกมาได้ 100% ค่า 0 คือ สามารถทำนายความสัมพันธ์ของตัวแปรต่าง ๆ ได้ 0% เป็นต้น
lr_train_mse = mean_squared_error(Y_train, Y_linear_train_prediction)
lr_test_mse = mean_squared_error(Y_test, Y_linear_test_prediction)
lr_train_r2 = r2_score(Y_train, Y_linear_train_prediction)
lr_test_r2 = r2_score(Y_test, Y_linear_test_prediction)
print("Train MSE:",lr_train_mse)
print("Test MSE:",lr_test_mse)
print("Train R²:", lr_train_r2)
print("Test R²:", lr_test_r2)
ผลลัพธ์คือ
Train MSE: 0.12719352133602765
Test MSE: 0.12013419062441164
Train R²: 0.48617221607759376
Test R²: 0.5182981429812116
จากผลลัพธ์จะเห็นได้ว่า Model เราเข้าใจความสัมพันธ์ของตัวแปรต่าง ๆ เพียงแค่ 48.6% เท่านั้นในข้อมูลที่เคยเจอมาก่อน (Train Set) ส่วนข้อมูลที่ไม่เคยเจอมาก่อน (Test Set) เข้าใจความสัมพันธ์ได้ 51.8%
การ Train Model แบบ Polynomial
เนื่องจาก Linear Regression อธิบายง่าย ๆ เสมือนการลากเส้นผ่าน Data Points ไปแบบตรง ๆ สำหรับข้อมูลที่ไม่ได้ซับซ้อนมาก สามารถลากเส้นตรงตัดผ่าน แล้วคำนวณจาก Regression Line ได้เลย Linear Regression ก็อาจใช้ทำนายได้ แต่สำหรับข้อมูลที่อาจจะซับซ้อนยิ่งกว่า ไม่สามารถลากเส้นตรงตัดผ่านได้ การใช้ลากเส้นแบบ Polynomial จึงจะให้ผลที่ใกล้เคียงความเป็นจริงมากกว่า ดังภาพ
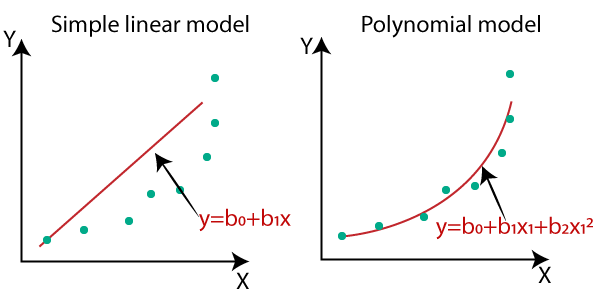
ขอบคุณภาพจาก medium.com/analytics-vidhya/understanding-polynomial-regression
การพยายามลากเส้นผ่านข้อมูล ก็คือการ Train Model นั้นเอง ดังนั้น หากเราจะแก้โค้ดเก่าของเรา เราจะแก้ไขส่วนที่เป็น SelectKBest ดังนี้ โดยผมจะกำหนด PolynomialFeatures(2) ตัวเลขสองคือ Degree ของ Polynomial นั่นเอง Degress 1 ก็คือ Linear Polynomial หรือเส้นตรง (Linear) ธรรมดา Degree 2 ก็คือ Quadratic Polynomial ส่วน Degree 3 ก็คือ Cubic Polynomial
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import f_regression
from sklearn.preprocessing import PolynomialFeatures
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
selector = SelectKBest(score_func=f_regression, k=12)
X_train_selected = selector.fit_transform(X_train, Y_train)
X_test_selected = selector.transform(X_test)
#Degree = 2
poly = PolynomialFeatures(2)
X_train_poly = poly.fit_transform(X_train_selected)
X_test_poly = poly.transform(X_test_selected)
จากนั้นก็ถึงจะสามารถนำไป Fit และ Predict ดังนี้
lr = LinearRegression()
lr.fit(X_train_poly, Y_train)
Y_linear_train_prediction = lr.predict(X_train_poly)
Y_linear_test_prediction = lr.predict(X_test_poly)
lr_train_mse = mean_squared_error(Y_train, Y_linear_train_prediction)
lr_test_mse = mean_squared_error(Y_test, Y_linear_test_prediction)
lr_train_r2 = r2_score(Y_train, Y_linear_train_prediction)
lr_test_r2 = r2_score(Y_test, Y_linear_test_prediction)
print("Train MSE:",lr_train_mse)
print("Test MSE:",lr_test_mse)
print("Train R²:", lr_train_r2)
print("Test R²:", lr_test_r2)
อ้างอิง:
www.freecodecamp.org/news/what-is-r-squared-r2-value-meaning-and-definition/
www.simplilearn.com/tutorials/statistics-tutorial/mean-squared-error

- Name (Pen name): Sunny Jirakit (Sunny420x)
- Study: Bachelor Degree of Computer Science from Chiang Mai Rajabhat University
- Personality: Architect (INTJ-T)
- Experience: JavaScript, Angular.js, React.js, Next.js Express.js, Unity C#, Socket.io
- Hobby: Organic Chemistry